
Putting things simply to begin with, Artificial Intelligence (AI) generally refers to intelligent tasks carried out by computers. Artificial intelligence is normally a ‘generalization’ term commonly used for its sub-fields such as machine learning, deep learning, natural language processing, etc. All the above-mentioned abilities include the deep skills to solve complicated problems, find significance in large data sets, derive important information from previous experiences, and make general observations. Although now in trend, it is proved that machines can be programmed in such a way that they can perform tasks like automating games. Now in more spotlight than ever, the field of AI was and will always be ever-evolving. With the increase in demand for the field of AI in several domains such as computer search engines, Health care, Education, and many more.
Machine learning is a branch of artificial intelligence (AI) that is trained on data using various algorithms to solve certain problems. Some practical examples of applications of machine learning are Recommendation systems in websites, Image recognition, etc.
After training the machine through data and algorithms, the application is capable of making classifications or predictions and uncovering key insights from data. Machine learning is primarily built on mathematical principles hence boosting the significance of mathematics in machine learning. The underlying mathematical concepts mostly used in AI algorithms are:
- Linear Algebra
- Calculus
- Probability theory
- Discrete Maths
- Statistics
The concept of linear algebra in Machine learning
Linear algebra is a foundational mathematical concept essential for delving into the realm of machine learning. A grasp of constructing and understanding linear equations is pivotal in developing key machine learning algorithms, aiding in the evaluation and observation of data sets. It plays a critical role in algorithms like linear regression and concepts such as loss functions, regularization, covariance matrices, Singular Value Decomposition (SVD), Matrix Operations, and support vector machine classification. Linear algebra is also integral in reducing data dimensionality through techniques like Principal Component Analysis (PCA). Furthermore, it holds significant importance in neural networks, influencing their processing and representation.
Applications:
- Ranking results (with eigenvectors)
- Solving for unknowns in the machine learning algorithms
- Reducing dimensionality (Principal Component Analysis)
- Recommendation systems (Singular value decomposition)
- Natural language processing (Singular value decomposition, matrix factorization)
Tensors:
- In the world of machine learning, technologies such as TensorFlow, Tensor lab, Deep Tensorized Networks, and Tensorized LSTMs have “Tensor” in their name. But what actually are tensors? and how it relates to machine learning, which we will explore below.
The word tensor is derived from the Latin word ‘tensus’ which means stress or tension. As the tensor progresses from a single number(scalar) to a vector to a matrix and n-dimensions, information is being added at every step. Tensor is a simple mathematical concept. It is a generalization of scalars, vectors, and matrices to higher dimensions.
- Tensors in relation to machine learning:
To relate tensors with machine learning, we have to keep in mind that data (an integral part of ML) are often multi-dimensional. So, tensors play a vital role in Machine learning by encoding multi-dimensional data. For example: A 3D tensor for student exam scores, where each student’s scores in three subjects are represented as a 3D array. Each dimension corresponds to students, exams, and individual subject scores, respectively. So, in machine learning, we can think of tensors as boxes that hold and keep track of different pieces of information.
| Dimensions | Mathematical Name | Description |
| 0 | Scalar | magnitude |
| 1 | Vectors | Array |
| 2 | Matrix | Square |
| 3 | 3-tensor | Cube(3D) |
| n | n-tensor | Higher dimensional |
- Scalar:
- Generally, a scalar is a quantity that has only magnitude(size) meaning it has no direction. It is represented by a single numerical value. It is usually referred to as “0-dimensional tensors”. Scalars can undergo arithmetic operations such as addition, subtraction, multiplication, and division. The example usage of scalar representation is Mass, time or temperature. All three examples only have a magnitude (5 kgs, 5 seconds, and 5 degrees Celsius respectively).
- Vectors:
- While scalars are zero-dimensional and only have magnitude, vectors on the other hand are mathematical entities that extend the concept of scalars by incorporating both magnitude and direction.
- Vectors are one-dimensional arrays of numbers.
- For example: Velocity, force, and acceleration are often represented as vectors. A velocity vector of v= [5 m/s,2 m/s2] v=[5m/s,2m/s2] indicates a speed of 5 meters per second in the x-direction and an acceleration of 2 meters per second squared in the y-direction.
- Matrix:
- Similar to vectors, matrix tensors extend the concept of scalars by incorporating both magnitude and direction in multiple dimensions. While vectors are one-dimensional arrays, matrix tensors are two-dimensional arrays of numbers.
- Matrices consist of rows and columns, and each element in the matrix represents a scalar value. Tensors, in a broader sense, can have more than two dimensions.
- For example, a matrix tensor A can be represented as:
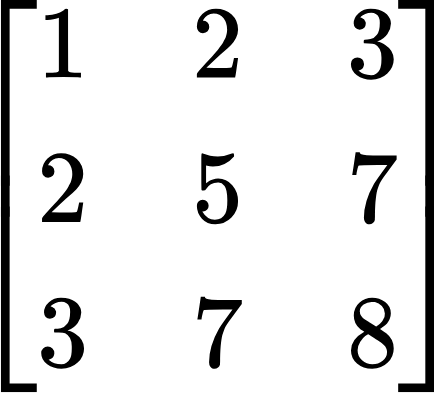
The size of the above matrix is 3×3.
Tensors play a pivotal role in machine learning, serving as the fundamental data structure that enables the efficient representation and manipulation of multidimensional arrays. In various machine learning algorithms, especially those implemented using deep learning frameworks like TensorFlow and PyTorch, tensors are extensively utilized. Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and deep neural networks rely heavily on tensors to store and process data. Tensors are employed to represent input data, weights, and biases in these models, facilitating parallel computation and optimization processes. Moreover, tensor operations form the backbone of forward and backward passes during training, where gradients are computed for parameter updates. The ability of tensors to integrate with GPU acceleration further enhances the efficiency of training large-scale models. In summary, using tensors in machine learning is foundational to the implementation and success of algorithms, providing a versatile and scalable framework for handling complex data structures in deep learning applications.
References
Chakraborty, A. (2023). How to learn mathematics for machine learning. How to learn mathematics for machine learning, 1. Retrieved from https://www.analyticsvidhya.com/blog/2021/06/how-to-learn-mathematics-for-machine-learning-what-concepts-do-you-need-to-master-in-data-science/
Copeland, B. (2024). artificial intelligence. artificial intelligence, 8. Retrieved from https://www.britannica.com/technology/artificial-intelligence
kan, E. (2018). Quick ml concepts. tensors, 1. Retrieved from https://towardsdatascience.com/quick-ml-concepts-tensors-eb1330d7760f
Kolecki, J. C. (2002). An introduction to Tensors for students of Physics and Engineering. An introduction to Tensors for students of Physics and Engineering, 29. Retrieved from https://www.grc.nasa.gov/www/k-12/Numbers/Math/documents/Tensors_TM2002211716.pdf