
So you want to become a web developer. But but do you know about the web?? Or the internet??

I assume the answer is “A little” or “No, That’s why I am here”.
What knowledge should I have before starting this course??
-HTML, CSS, JavaScript, TypeScript.

Just kidding, you can start this course with zero knowledge of the web. Well, I guess it’s safe to assume that you know how to use the Internet (The fact that this course is on the Internet itself). So yeah, that is all that you need for this course.
Also also also, the course might turn a bit boring sometimes(0.0001% of the time) due to the theories and all.
Let’s start with a short introduction to World Wide Web (WWW) and then we shall jump to the Internet.

WWW-

The web, short for World Wide Web, is a vast network of interconnected documents and resources that can be accessed through the Internet. It’s like a giant web of information that connects people(devices) from all around the world.
Imagine the web as a massive library where you can find books, magazines, articles, and all sorts of information. Each of these resources is like a webpage, and they are all connected through links. Just like in a library, you can explore different sections, move from one book to another, and find related information by following the links.
Now let’s have a basic understanding of how the Internet works and then we will learn more about the web. Don’t worry if you get introduced to new terms during the explanation. They will be discussed in the further part of the course.
Internet

The Internet is a global network that connects computers and devices all over the world. It works by transmitting data between these devices through a complex system of networks and protocols.
Here’s a simplified explanation of how the Internet works:
Devices and Connections: One quick question, how are you connected to the Internet right now??
- It might be either wireless with the help of wifi or with the help of a mobile network or wired connected by ethernet cables.

Fig: Ethernet Cable
Devices like computers, smartphones, and servers are connected to the Internet through various means such as Wi-Fi, Ethernet cables, or mobile networks.
Now how will the internet distinguish between your device and other devices??
- Here comes the concept of the IP address.
Each device is assigned a unique address called an IP (Internet Protocol) address, which helps identify it on the Internet.
Data Packets:
Like us humans, the internet is also weak. It takes a lot of time to transfer big data. Unlike the real world, we can chop data and then rejoin them without damaging the originality.
So when you send or receive information over the internet, it is broken down into small chunks called data packets.
Example: When you send an image to your friend, the internet divides the image into small chunks (imagine as if the internet tears down your pictures into small pieces), also each piece is labeled so that they can be arranged in order. Now these pieces or chunks are sent to your friend through different paths over the internet. When the pieces reach your friend’s computer, they now combine to make the original picture. The same happens when you send a long message, a video, or anything on the internet.
These packets contain the data being transmitted, along with the necessary addressing and control information.
Routing:

Imagine you want to send a letter to your friend who lives in another city. To ensure that the letter reaches your friend, you need to find the best route for it to travel. This is where a router comes in.
A router is like a traffic director for information on the internet. It helps guide data packets, which are like small pieces of information, to their intended destinations. Just like roads connect different cities, routers connect different networks on the internet.
When you send a data packet over the internet, it doesn’t travel directly from your device to the destination. Instead, it hops through different routers and network switches along the way. Each router it encounters makes a decision about which path the packet should take to reach its destination.
Routers use something called routing protocols to make these decisions. Think of routing protocols as a set of rules that routers follow to find the most efficient path. These rules consider factors like the speed and reliability of different connections to determine the best route for each packet.
The goal of routing is to ensure that data packets reach their destination quickly and reliably. Routers work together to create a network of paths, just like a road system, that allows data to flow smoothly across the internet.
So, next time you send an email, browse a website or stream a video, remember that routers are busy directing the traffic of data packets to make sure your information gets to where it needs to go.
Transmission Protocols:
When you send data over the internet, it’s important to ensure that the data arrives intact and in the correct order. Transmission protocols are like safety measures that prevent your data from getting mixed up with others and ensure its reliable delivery.
One commonly used transmission protocol is TCP (Transmission Control Protocol). TCP breaks your data into smaller units called packets. Each packet is given a number to keep track of the order in which they were sent. This numbering allows the receiving device to rearrange the packets correctly upon arrival.
TCP also performs error checking. It adds extra information to each packet, called a checksum, which helps detect if any errors occurred during transmission. The receiving device checks the checksum to verify the integrity of the packets. If any packets are found to be damaged or lost, the receiving device notifies the sender, and those packets are retransmitted.
This process of acknowledging and retransmitting packets ensures that your data arrives reliably and in the correct order. It’s like having a confirmation system in place to make sure nothing gets lost in transit.
Other transmission protocols, like UDP (User Datagram Protocol), are used when speed is prioritized over reliability. UDP doesn’t have the same error-checking and retransmission mechanisms as TCP. It’s commonly used for real-time applications, such as streaming video or online gaming, where a slight loss of data is acceptable.
So, thanks to transmission protocols like TCP, your data packets travel through the internet in an organized and secure manner, reaching their destination intact and in the right sequence.
Internet Service Providers (ISPs):

Internet Service Providers (ISPs) are companies that offer internet connectivity to users like you. They have their own networks, which are like large systems of interconnected devices and cables that enable internet access. ISPs connect their networks to each other to create a global network, allowing users from different ISPs to communicate and access information worldwide.
When you sign up for internet service with an ISP, they assign you something called an IP address. An IP address is a unique identifier that distinguishes your device on the internet. It’s similar to having a specific address for your home, but in this case, it’s for your device on the internet.
Your ISP’s network acts as the bridge between your device and the vast internet. They provide the necessary infrastructure and connectivity to ensure your device can connect to websites, send emails, stream videos, and perform other online activities.
Think of your ISP as the middleman between you and the internet. They handle the technical aspects of connecting you to the global network, managing the flow of data between your device and the websites or services you access.
So, when you subscribe to an internet service, your ISP plays a crucial role in providing you with an IP address, connecting you to their network, and ultimately allowing you to connect to the internet and explore all the digital wonders it offers.
Domain Names and DNS:

Instead of remembering complex IP addresses, we use domain names (e.g., www.google.com) to access websites. The Domain Name System (DNS) translates these domain names into IP addresses. When you enter a domain name in your web browser, your device queries DNS servers to find the corresponding IP address.
We will be discussing more about this in a further part of the lesson.
Web Servers and Clients:

When you want to access a website or any online content, it needs to be stored somewhere. That’s where web servers come in. Web servers are special computers that store websites and web resources, such as images, videos, and files.
Think of a web server as a big library where websites are kept. Each website has its own place on the server, just like books have their shelves in a library. Web servers are designed to handle multiple requests from users and deliver the requested content efficiently.
Now, let’s say you want to visit a website. You open your web browser (such as Chrome or Firefox) and type in the website’s URL (Uniform Resource Locator) in the address bar. When you hit Enter or click Go, your browser sends a request to the appropriate web server where that website is hosted.
The web server receives your request and understands which website you’re asking for based on the URL. It processes your request and retrieves the relevant web page from its storage. The web page consists of HTML, CSS, images, and other resources that make up the website’s content.
Once the web server has gathered the requested web page, it sends it back to your browser as a response. Your browser receives the response and interprets the HTML and CSS to display the web page on your screen. Voila! You can now see and interact with the website you requested.
This process of your browser sending a request to a web server and receiving a response is the basis of how websites are accessed and displayed. It’s a back-and-forth communication between your browser (the client) and the web server, allowing you to explore the vast world of the internet.
So, next time you visit a website, remember that it’s being stored on a web server somewhere and delivered to your browser when you request it.
Protocols and Standards:

Protocols are a deep concept. For now, just understand that the Internet relies on various protocols and standards to ensure compatibility and interoperability among devices and networks. Some important ones include HTTP (Hypertext Transfer Protocol) for web browsing, SMTP (Simple Mail Transfer Protocol) for email, and FTP (File Transfer Protocol) for file transfers.
We will continue with protocols in the following lesson.
In summary, the Internet enables devices to connect and communicate globally through data packets, routers, transmission protocols, ISPs, domain names, web servers, and various protocols and standards. It’s a remarkable network that allows us to access and share information, communicate, and collaborate on a global scale.
Wow, you just got the idea of how the Internet works. Isn’t it amazing?
Client-Server Architecture:
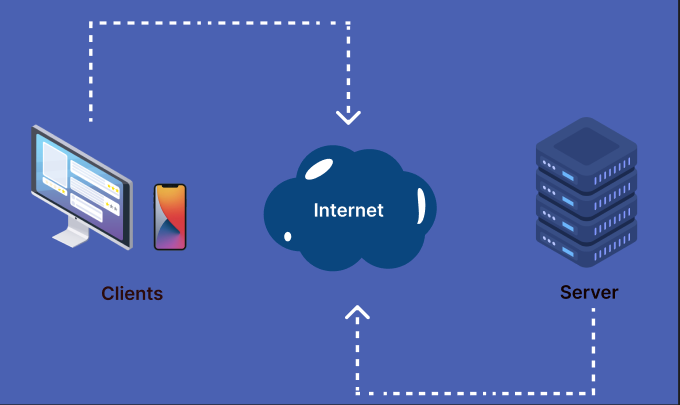
Before starting let me ask you a question. What do you mean by client and server? Well basically client is a device that requests services and the server is the computer that provides the services.
Now what is the architecture referring to?
It defines how different components or modules of a system are organized, how they interact with each other, and how the system as a whole operates.
Now can you guess what client-server architecture is??
Yeah, you got it.
It’s an architecture that defines the relationship between clients and servers in a networked environment.
When it comes to the web, the client-server model is fundamental to how it operates. Web browsers such as Chrome, Firefox, or Safari act as clients, and they communicate with web servers to retrieve web resources such as HTML pages, images, videos, or other types of files. This is what we as a user see. Let’s dive inside of how the web operates based on the client-server model:
Client sends a request: The client (web browser) sends a request to the server for a particular resource. For example, when you enter a URL in your browser’s address bar and press Enter, the browser initiates an HTTP request to the corresponding web server.
Wait wait wait, what is HTTP? Well for now just understand HTTP is a protocol used for transmitting and retrieving web resources, such as web pages, over the Internet. We will learn more about it in the further course.
Server receives the request: The web server receives the request from the client and processes it. The server is typically a computer or a cluster of computers dedicated to hosting and serving web content. They are big supercomputers.
Server processes the request: The server analyzes the client’s request to determine the requested resource and the appropriate action to take. This could involve fetching data from a database(fetching means to extract data from online storage), executing server-side scripts, or retrieving files from the server’s file system.
Server generates a response: Based on the request, the server generates a response that includes the requested resource or performs the requested action. This response is typically in the form of an HTTP response, which includes a status code, headers, and the actual content.
Server sends the response: The server sends the generated response back to the client over the network. The response travels through various network layers and protocols until it reaches the client.
Client receives the response: The client (web browser) receives the response from the server and begins processing it. The response may include HTML content, which the browser interprets to render the web page. It can also include additional resources like CSS files, JavaScript code, or images referenced in the HTML.
Client renders the content: The web browser renders the received content, displaying it to the user on their device’s screen. The browser interprets the HTML, applies styles from CSS files, and executes any embedded or referenced JavaScript code to provide an interactive experience.
This client-server interaction happens continuously as users navigate the web. Each time a new resource is requested, the client sends a new request to the server, and the cycle repeats.
URL

You must have heard about URLs, it might be asking your friends for the URL of videos and pictures on the internet. Ever wonder what actually they are?? Well, you must have a basic idea of URL as an address to the contents of the web. You are right. Why not do some addition to your knowledge?
A URL (Uniform Resource Locator) is a string of characters that serves as a unique address to identify resources on the web. It specifies the protocol, domain name, path, and optional parameters required to locate and retrieve the desired resource.
URL Structure:
Let’s understand each component of a URL.
1. Protocol: The protocol specifies the method of communication to access the resource. It determines how data will be transmitted between the client (your web browser) and the server (where the resource is hosted). The two common protocols are HTTP and HTTPS. And, yeah we will just get to HTTP after this. I promise.
Example:
HTTP: http://example.com
HTTPS: https://example.com
2. Domain Name: The domain name identifies the specific website or server where the resource is located. It is the human-readable address that you type into your browser to access a website.
Example:
Domain Name: google.com
3. Path: The path represents the specific location of the resource within the server’s file system or website structure. It indicates the directories and subdirectories leading to the desired resource.
Example:
Path: /images/puppy.jpg
Putting it together:
URL: https://www.example.com/images/puppy.jpg
In this example, the protocol is HTTPS, the domain name is www.example.com, and the path is /images/puppy.jpg. So, the URL points to an image file named “puppy.jpg” located in the “images” directory on the website www.example.com.
4. Optional Parameters: Optional parameters, also known as query parameters, provide additional information or instructions to the server. They are appended to the URL after a question mark (?) and separated by ampersands (&). Parameters consist of key-value pairs.
Example:
URL: https://www.example.com/search?q=dogs&category=pets
In this example, the URL includes optional parameters “?q=dogs” and “?category=pets”. Here, the parameter “q” with the value “dogs” indicates a search for the keyword “dogs,” while the parameter “category” with the value “pets” specifies the search category as “pets.”
Now the next time you see a URL, you know how it works.
HTTP:

Finally, after a long wait we are here.
Till now you must have got a basic overview of HTTP. It’s a rule to communicate between the browser and the server. Now let’s see how it communicates.
First, let’s begin with a formal introduction.
HTTP stands for Hypertext Transfer Protocol. It is the underlying protocol used for communication between clients (such as web browsers) and servers (which host websites) on the internet. In other words, it’s the language that allows your web browser to talk to the web server and retrieve web pages.
HTTP Request:
When you type a website address into your browser’s address bar and hit enter, your browser sends an HTTP request to the server hosting that website. An HTTP request consists of three main parts: the request method, headers, and an optional body.
Request Method: The request method indicates the type of action you want the server to perform. The most common methods are:
GET: Used to retrieve information from the server. For example, when you visit a website, your browser sends a GET request to fetch the web page.
POST: Used to send data to the server to create or modify something. For instance, when you submit a form on a website, your browser sends a POST request with the form data.
Headers: Headers contain additional information about the request. They provide details such as the type of content the client can accept, the language preference, and more. For example, the “User-Agent” header tells the server which web browser you’re using.
Body: The body is an optional part of the request used for sending additional data to the server, typically with methods like POST. It can contain form data, JSON, or other types of content.
Let’s understand it with an example:
Imagine you’re ordering a pizza from a website. When you click the “Order Now” button, your browser sends an HTTP request to the pizza server. Here’s a simplified example of the request:
makefile
| POST /order HTTP/1.1 Host: www.pizzashop.com Content-Type: application/json Content-Length: 45 { “pizzaSize”: “large”, “toppings”: [“pepperoni”, “mushrooms”], “deliveryAddress”: “123 Main St” } |
Request Method: In this example, the request method is POST because you’re sending data to the server to create a new order.
Headers: The request includes headers like Host, which specify the domain name of the pizza server. Content-Type indicates that the body of the request is in JSON format, and Content-Length specifies the length of the request body.
Body: The body contains the details of your order in JSON format. It includes the pizza size, toppings, and delivery address.
HTTP Response:
After receiving your order request, the pizza server processes it and sends back an HTTP response. Here’s a simplified example:
| HTTP/1.1 200 OK Content-Type: application/json Content-Length: 36 { “orderId”: “123456”, “estimatedDeliveryTime”: “30 min” } |
Status Line: The status line indicates that the request was successful, as it returns a 200 OK status code.
Headers: The response includes headers such as Content-Type, which specifies that the response body is in JSON format, and Content-Length, indicating the length of the response body.
Response Body: The response body contains the server’s response in JSON format. It includes an orderId to identify your order and an estimatedDeliveryTime specifying the approximate time it will take to deliver your pizza.
By following this example, your browser can interpret the response, display the order confirmation on the website, and provide you with an estimated delivery time.
Remember, this is a simplified explanation of the HTTP request and response process. In real-world scenarios, there may be additional headers, more complex request structures, and various status codes and response formats depending on the specific application or API being used.
Now what is HTTPS then??

HTTPS stands for Hypertext Transfer Protocol Secure. It is a secure version of the HTTP protocol. While HTTP sends data as plain text, HTTPS adds an extra layer of security by encrypting the data transmitted between the client and the server.
When you visit a website that uses HTTPS, the communication between your browser and the website’s server is encrypted, ensuring that no one can intercept or tamper with the data being transmitted. This is particularly important when sensitive information such as passwords, credit card details, or personal information is being exchanged.
HTTPS uses a protocol called SSL (Secure Sockets Layer) or its successor, TLS (Transport Layer Security), to establish an encrypted connection. This encryption process involves the use of cryptographic keys that are exchanged between the client and the server during the initial handshake.
The main difference between HTTP and HTTPS is the addition of SSL/TLS encryption in HTTPS. This encryption ensures that the data transmitted between the client and the server is secure and protected from eavesdropping or unauthorized access.
When you visit a website that uses HTTPS, you’ll typically see a padlock icon in the address bar of your browser, indicating that the connection is secure. The website’s URL will also begin with “https://” instead of “http://”.
Domain Name System (DNS)
Okay, Time for a question. What can you remember better? A number or a word?
For a normal human being you will answer words. And it’s a fact, we humans are not good at remembering numbers.

But in the case of computers it’s the opposite. Computers are very good with numbers. Now to help us as well as the computer DNS comes in.
What is DNS?
Imagine you want to visit a website, like www.example.com. DNS (Domain Name System) is like a phonebook for the internet. Instead of remembering and typing complicated IP addresses (a series of numbers) to access websites, DNS translates the easy-to-remember domain names (like www.example.com) into IP addresses that computers understand.
Why is DNS important?
When you enter a domain name in your web browser, DNS helps your computer find the correct server where the website is hosted. It’s like looking up a contact in a phonebook to get their phone number. DNS ensures that your computer connects to the right server to access the desired website.
Now, let’s outline the steps involved in DNS resolution using the example of visiting www.example.com:
Step 1: Requesting the IP address
When you type www.example.com in your web browser, your computer sends a request to a special server called a DNS resolver. It says, “Hey, I want to visit www.example.com. Do you know the IP address for it?”
Step 2: Checking the local cache
The DNS resolver checks its local cache, which is like a temporary storage of previously looked-up addresses. It’s similar to your browser remembering websites you’ve visited before. If the IP address for www.example.com is already in the cache, the resolver can provide it immediately without further steps. Otherwise, it moves to the next step.
Step 3: Asking other DNS servers
If the IP address is not in the cache, the resolver acts as a detective and starts asking other DNS servers for the information. It begins with the root DNS server.
Step 4: Root DNS server
The root DNS server is like the starting point of the internet. It doesn’t know the IP address of www.example.com, but it directs the resolver to the next server that can help, called the Top-Level Domain (TLD) DNS server.
Step 5: TLD DNS server
The TLD DNS server manages specific domain extensions, such as “.com.” It guides the resolver to the next server, which is the authoritative DNS server for the domain “example.com.”
Step 6: Authoritative DNS server
The authoritative DNS server is the one that knows the IP address for www.example.com. It has the final answer. The resolver contacts this server and asks, “What’s the IP address for www.example.com?”
Step 7: Obtaining the IP address
The authoritative DNS server responds to the resolver, saying, “The IP address for www.example.com is 192.0.2.1.”
Step 8: Returning the IP address
The DNS resolver receives the IP address from the authoritative server and shares it with your computer.
Step 9: Caching the IP address
Your computer’s DNS resolver stores the IP address in its cache for future reference. This way, if you visit the same website again, the resolver can quickly provide the IP address without repeating the entire process.
Step 10: Connecting to the website
With the IP address in hand, your computer can now connect to the appropriate server (192.0.2.1) hosting www.example.com. It establishes a connection and fetches the website content, allowing you to see the webpage in your browser.
That’s the basic process of DNS resolution. Obviously the processes are much more deep and complex but this is what you shall know as a begginer.
So, how has it been going so far. Little booring right? Yeah I get it. Lots of theories and all.
Here is a short question to cure your boredom.
What web-browser are you using??
That might not have cured your boredom but that is the topic of our next lesson.
Web Browser
A web browser is a software application that allows you to access and view websites on the internet. It acts as a window through which you can interact with web pages, search for information, and perform various online activities.
When you enter a website’s address (URL) into the address bar of a web browser and press Enter, the browser sends a request to the web server where the website is hosted. The server then sends back the requested web page, which the browser interprets and displays to you.
Rendering Process:
The rendering process involves several steps that the web browser follows to display a web page correctly. Here’s a simplified explanation of these steps:
Requesting the Web Page: The browser sends a request to the web server asking for the HTML document of the web page.
Downloading HTML: The browser receives the HTML file from the server. HTML (Hypertext Markup Language) is the standard language used to structure the content of web pages.
Parsing HTML: The browser parses (interprets) the HTML file to understand its structure and elements. It identifies the different parts of the web page, such as headings, paragraphs, images, links, and more.
Building the Document Object Model (DOM): The browser creates a Document Object Model (DOM) tree based on the parsed HTML. The DOM represents the structure of the web page as a hierarchical tree of objects, where each element, attribute, and text node is represented as a distinct object.
Downloading External Resources: If the web page contains external resources like images, stylesheets, or JavaScript files, the browser starts downloading them simultaneously.
Parsing CSS: Cascading Style Sheets (CSS) define the visual appearance and layout of the web page. The browser parses the CSS files associated with the web page and applies the styles to the appropriate elements in the DOM.
Rendering the Web Page: Using the DOM and CSS information, the browser starts rendering the web page on the screen. It calculates the layout, positions the elements, and displays the content.
Executing JavaScript: If the web page includes JavaScript code, the browser executes it. JavaScript adds interactivity and dynamic functionality to web pages. It can modify the DOM, make network requests, handle user interactions, and more.
Handling Events: The browser listens for user actions, such as clicks or keystrokes, and triggers appropriate event handlers specified by the JavaScript code.
Displaying the Web Page: Finally, the browser displays the fully rendered web page in its window, allowing you to see and interact with the content, click on links, submit forms, and perform other actions.
Popular web browsers include Google Chrome, Mozilla Firefox, Microsoft Edge, Apple Safari, and Opera. These browsers use different rendering engines (software components responsible for rendering web pages), such as Blink (used by Chrome), Gecko (used by Firefox), WebKit (used by Safari), and Trident (used by older versions of Internet Explorer).
Each browser may have its unique features and interface, but they all follow similar principles to render and display web pages.
Security

What about Security then?? How do these big websites like Google, Facebook, etc secure their data??
- We already discussed the answer in the previous part of this lesson. Remember?
- Yes yes, HTTPS. Wow, that rhymes. Well, let’s learn a little more about it.
HTTPS is an important aspect of web security as it helps protect the confidentiality, integrity, and authenticity of the data transmitted between a web browser (client) and a website (server). It ensures that the communication between the two parties is secure and cannot be easily intercepted or tampered with by malicious attackers.
Here’s a simple analogy to understand the concept: Imagine you want to send a secret message to your friend. You put your message inside a locked box and give the key to your friend separately. This way, even if someone manages to get hold of the box during transit, they won’t be able to unlock it without the key.
Similarly, HTTPS uses encryption and authentication techniques to make sure that your web communication remains private and secure. When you visit a website secured with HTTPS, your web browser and the server establish a secure connection using SSL/TLS protocols.
SSL (Secure Sockets Layer) and its successor TLS (Transport Layer Security) are protocols that provide a secure channel for data exchange between a client and a server over the internet. They use cryptographic algorithms to encrypt the data and ensure its integrity.
Here’s another analogy to understand SSL/TLS: Imagine you want to send a letter to a friend, but you want to make sure no one can tamper with it. You seal the letter in an envelope, write your friend’s address on it, and put your signature across the seal. When your friend receives the letter, they can verify the seal and the signature to ensure the letter wasn’t opened or modified during transit.
In the case of SSL/TLS, when you connect to a website using HTTPS, your browser and the server perform a handshake process. During this handshake, they exchange encryption keys and establish a secure connection. This connection ensures that any data you send or receive from the website remains confidential and cannot be easily intercepted.
To illustrate this, let’s say you visit an online shopping website and want to enter your credit card details to make a purchase. If the website uses HTTPS, your credit card information is encrypted before it leaves your browser and travels to the server. This encryption makes it extremely difficult for anyone eavesdropping on the network to access or decipher your sensitive information.
In summary, HTTPS and SSL/TLS are essential for securing web communications by encrypting data and verifying the authenticity of the website. This ensures that your personal information, such as passwords, credit card details, and other sensitive data, is protected while browsing the web.
Additional Information

We have learned so much about the web, or have we??
Just kidding. Why not add some additional knowledge so that you can be a webmaster among your friends?
You must have come across this message many times.

Ever wonder what they actually mean? Is there a bundle of cookies waiting for being delivered to you? Sadly the answer is no. But cookies have an important role in the web.
Cookies:

Cookies are small text files that are stored on your computer or device by websites you visit. They serve multiple purposes, but their main role is to store information about your browsing session and preferences. When you visit a website, it may send a cookie to your browser, which then stores it on your device.
Cookies have various uses, such as:
– Session management: Cookies help websites remember who you are as you navigate different pages. For example, when you log into a website, a cookie is often created to keep you logged in as you move around the site. Without cookies, you would need to log in repeatedly.
– Personalization: Cookies can store your preferences, such as language settings or customized layouts. This allows websites to deliver a personalized experience tailored to your preferences.
– Tracking: Some cookies are used for tracking user behavior, such as analyzing website traffic or displaying targeted advertisements based on your browsing habits.
Here’s an example to illustrate how cookies work: Let’s say you visit an online shopping website and add items to your shopping cart. The website uses a cookie to remember the items in your cart. Even if you leave the website and come back later, the cookie helps the website remember what you had in your cart.
Caching:
Don’t tell me you don’t know what cache is.

Caching is a technique used to improve the performance and speed of websites. When you visit a website, your browser retrieves various resources like images, CSS files, and scripts from the web server. Caching allows these resources to be stored temporarily on your device or in a server closer to you.
By storing copies of these resources closer to the client (your browser or device), subsequent visits to the same website can be faster because the browser can retrieve the resources locally instead of making a round trip to the server. This reduces the time it takes to load a webpage, improving overall performance.
For example, let’s say you visit a news website that has caching enabled. The first time you visit the site, your browser retrieves all the images, CSS files, and scripts from the web server. However, these resources are also cached on your device. When you revisit the same website or navigate to another page on the site, your browser can use the cached resources, resulting in faster loading times.
Web standards and protocols:
Web standards and protocols are essential guidelines and rules that ensure compatibility, interoperability, and consistency on the World Wide Web. Here are some important ones:
– HTML5 (Hypertext Markup Language): HTML5 is the latest version of the standard markup language used to structure and present content on the web. It provides improved support for multimedia elements, semantic tags, and offline web applications.
– CSS3 (Cascading Style Sheets): CSS3 is a style sheet language used to describe the presentation and layout of HTML documents. It allows web designers to control the appearance of web pages by specifying fonts, colors, spacing, and more.
– XML (eXtensible Markup Language): XML is a flexible markup language used for structuring and storing data. It is often used for data exchange between different systems or platforms.
– JSON (JavaScript Object Notation): JSON is a lightweight data-interchange format that is easy for humans to read and write, and easy for machines to parse and generate. It is widely used for transmitting data between a server and a web application, often in the form of API responses.
– REST (Representational State Transfer): REST is an architectural style and set of principles for building scalable and interoperable web services. It emphasizes the use of standard HTTP methods (GET, POST, PUT, DELETE) and URLs to perform operations on resources.
These standards and protocols provide a common foundation for web development, ensuring that websites and web applications can work together seamlessly across different devices and platforms.
CONGRATULATIONS!!! You are a webmaster now.

Now you can kickstart your journey as a web developer(after learning some web languages).
